
Blog
Cloudflare Outage Shuts Down Thousands of Websites: What Really Happened & Key Lessons for Businesses
Nov
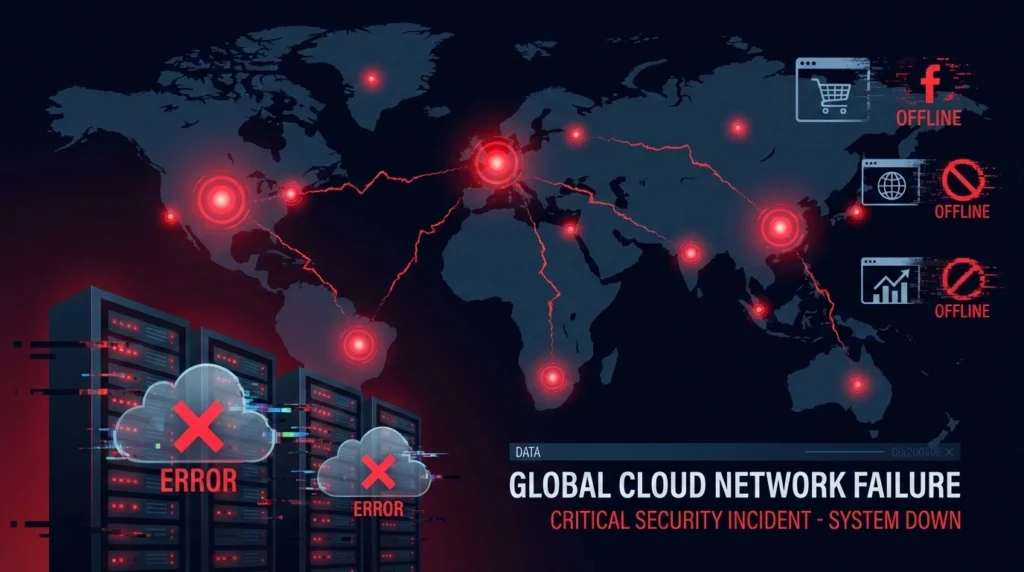
On 18 November 2025, a major outage at Cloudflare caused massive disruption across the internet. From global platforms like ChatGPT, X (Twitter), Canva, Spotify, IKEA, and several government portals, to small businesses and SaaS startups — websites across the world became slow, unreachable, or completely offline.
For many users it felt like “the internet is broken.” But the issue wasn’t with the apps themselves — the problem was at the infrastructure layer. Cloudflare is one of the world’s largest internet security and CDN providers, powering traffic management, DDoS protection and performance for more than 20% of global websites. When Cloudflare experiences a fault, the effects ripple across the internet instantly.
In this article we break down:
- What caused the Cloudflare outage
- Which services were affected
- How businesses were impacted
- Key lessons for website owners & developers
- How to avoid such risks in the future
What Happened During the Cloudflare Outage?
The outage began around 6:40 AM ET and thousands of websites suddenly began returning connection errors or failing to load. Reports quickly surged across platforms like Downdetector confirming that websites depending on Cloudflare were unreachable.
According to early explanations from Cloudflare engineers, the issue was triggered by a configuration update related to network traffic filtering, which unexpectedly overloaded internal systems and caused service failures across multiple global regions. Importantly, no malicious attack or cyber breach was involved — this was a technical failure triggered by internal infrastructure.
Cloudflare deployed a fix in phases and services were mostly restored by early evening IST. However, many businesses experienced multi-hour downtime.
Why the Impact Was So Huge
Cloudflare is a backbone component of the modern web. It is used for:
- CDN (Content Delivery Network) to speed up sites globally
- DDoS protection against attacks
- DNS management
- Security firewalls
- Traffic routing & caching
When any of these systems break, affected websites cannot load — even if their servers are functioning normally.

Major services affected included:
- ChatGPT
- X (Twitter)
- Canva
- Spotify & Apple Music related services
- IKEA & multiple e-commerce stores
- UK government websites
- SaaS tools, analytics platforms, and online education services
- Many startup and personal websites
The outage reminded everyone how centralized infrastructure dependency can turn into a single point of failure.
How This Outage Impacted Businesses
For many companies, even a few hours of downtime means direct losses:
- Lost customer transactions
- Support tickets flooding due to panic
- Drop in ad revenue & marketing performance
- Damage to brand trust
- Productivity interruption for online tools
Social media filled with questions like “Why is everything down?” — and many users blamed websites themselves without realizing the upstream issue.
What Website Owners Can Learn from This Incident
1. Avoid relying on a single provider
If your DNS, CDN, and security are all tied to one vendor, you have a single failure point.
Consider multi-CDN or backup DNS routing to keep core services online.
2. Enable fallback and cached versions
Serve static offline pages or cached content when the network collapses.
3. Monitor provider status
Use real-time status notifications and alerts so your team knows before your customers do.
4. Communicate transparently with users
A quick message like:
“We’re experiencing upstream provider issues. Services will be restored shortly.”
helps maintain trust and reduce confusion.
5. Prepare an incident-response plan
Downtime is inevitable — preparation makes all the difference.
A Bigger Question: Is the Internet Too Centralized?
More and more businesses rely on a few global players such as Cloudflare, AWS, Google Cloud and Microsoft Azure. While these services improve speed and security, they also increase risk — if one goes down, a huge part of the internet collapses with it.
This outage has already sparked discussions around:
- Multi-cloud architecture
- Open-source networking alternatives
- Localized traffic routing systems
- Distributed infrastructure rather than global dependency
Conclusion
The November 2025 Cloudflare outage exposed how fragile modern internet infrastructure can be — and how a small technical misconfiguration can temporarily break global connectivity.
The good news: Cloudflare resolved the issue within hours and confirmed that it wasn’t the result of a cyberattack.
The bad news: If businesses do not build redundancy, similar outages will continue to hurt revenue and user-experience.
The future belongs to companies that plan for reliability, not just performance.